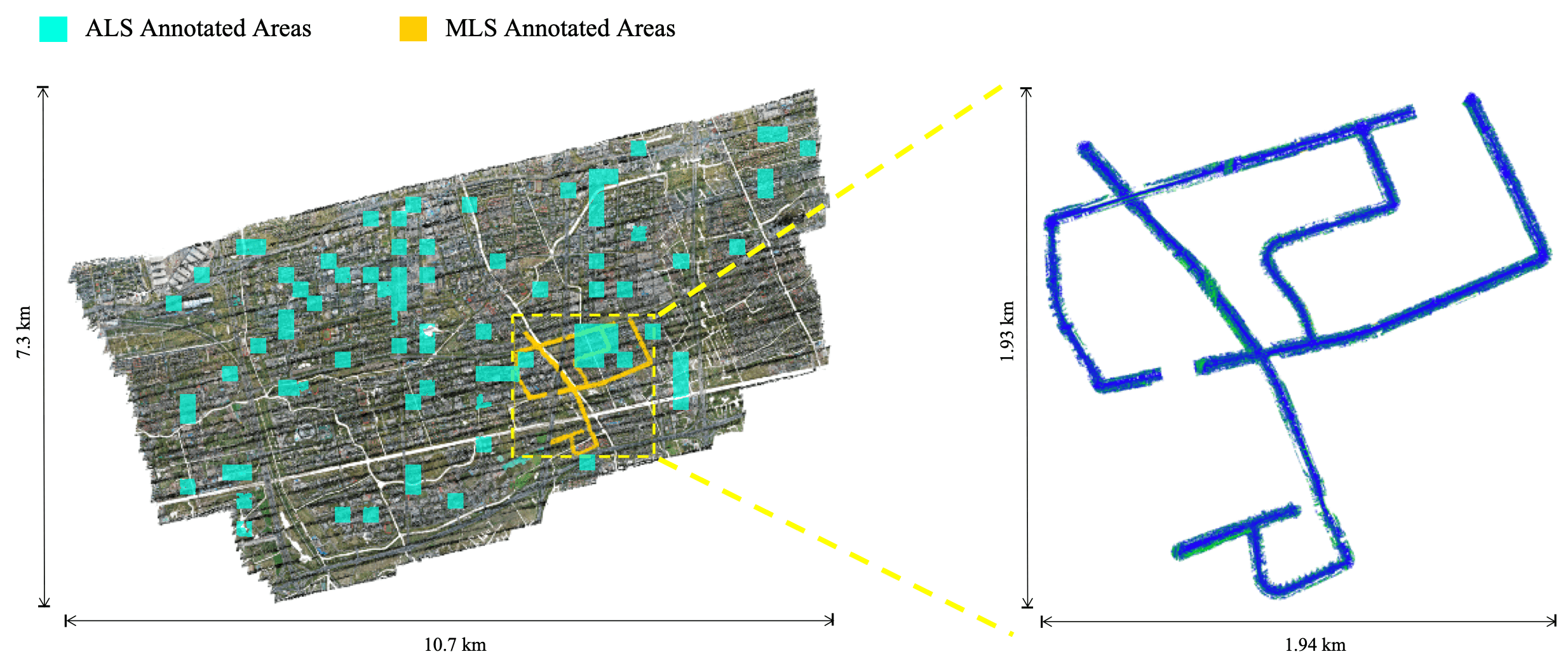
WHU-Urban3D includes ALS and MLS point cloud. ALS point cloud covers more than 3.6 × 106 m2 . For the purpose of convenient annotation, the whole area of ALS point cloud is divided into thousands of 200m ⨉ 200m blocks, of which more than 80 blocks are chosen for annotation.
Compared with the existing dataset for segmentation, WHU-Urban3D has the following advantages:

Semantic Annotation

Instance Annotation
Annotated Area
We segmented the roads into small parts, all of which cover a certain length and selected discontinuous and somewhat different parts for training and testing.
Annotation
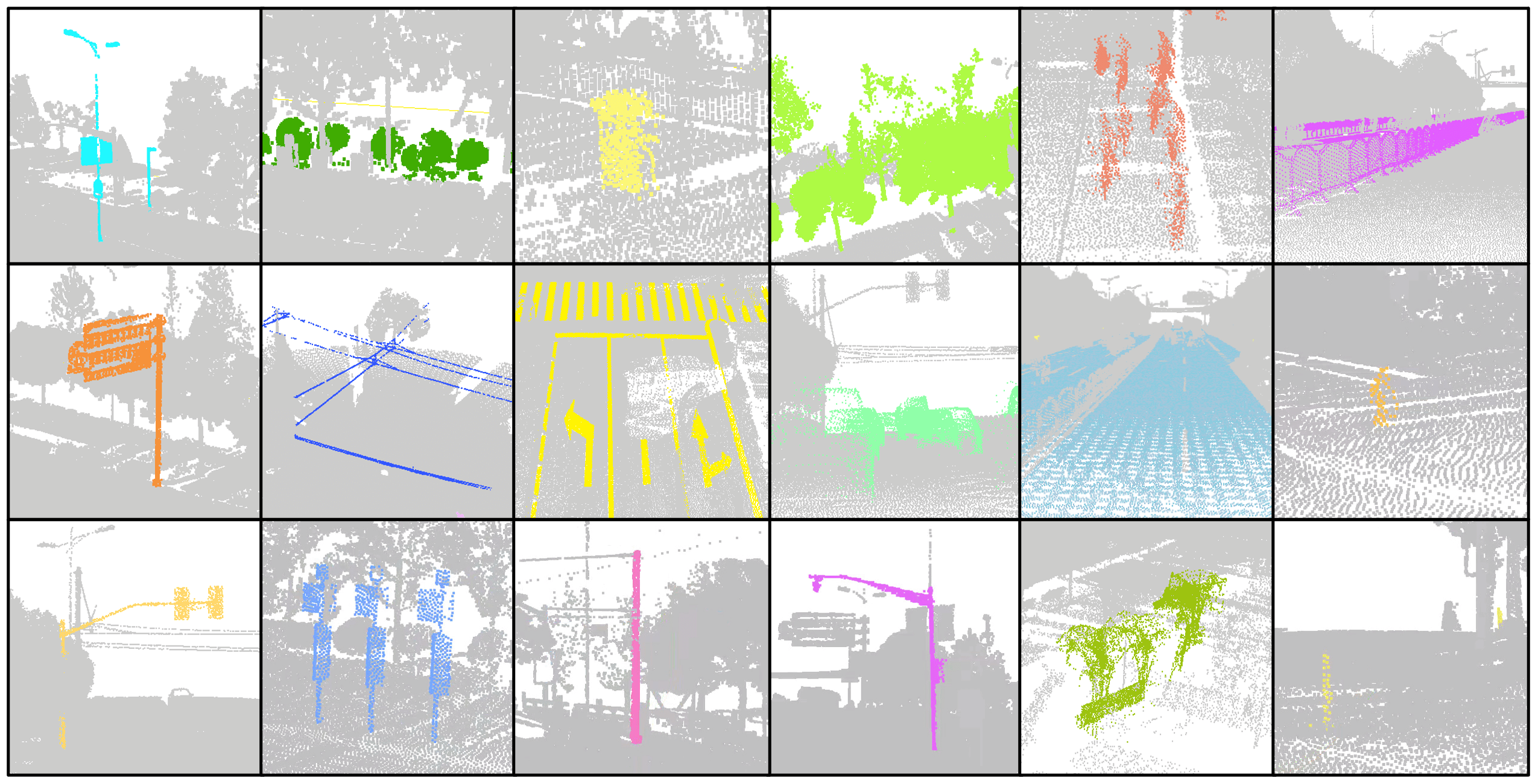
The process of annotating the dataset has been carried out based on a set of criteria. Firstly, every point in the scene has been classified to a specific category, which is particularly crucial for semantic segmentation. Each point has been assigned to a single class to ensure that there is no ambiguity in the dataset. Secondly, the points of countable objects like people and cars have been labeled instance by instance, enabling a detailed analysis of each object in the scene. Points of different instances have been segmented into different clusters with different instance labels, while points of the same instance have been segmented into the same cluster with the same instance label.
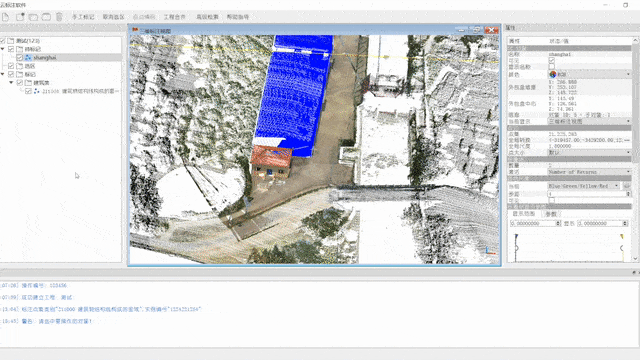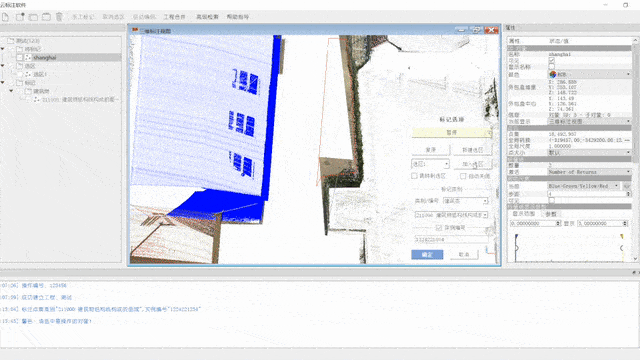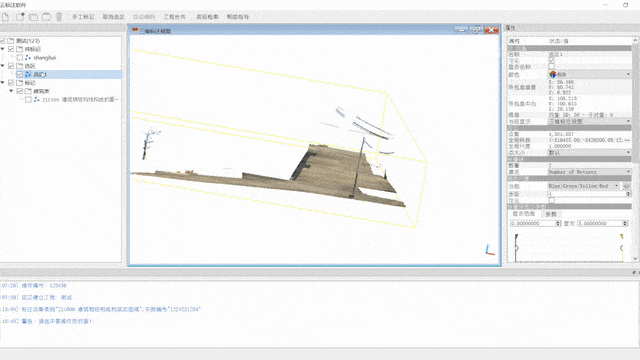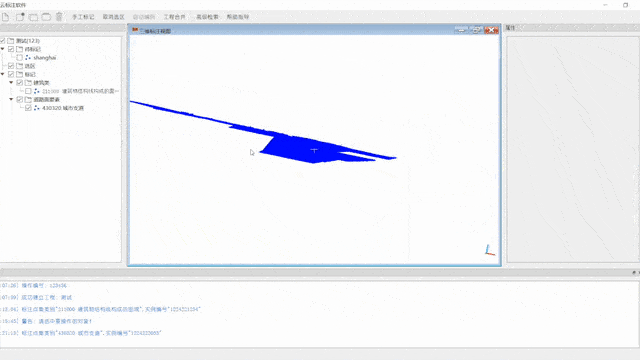
Thirdly, To further enhance the quality of the dataset, outliers and meaningless points have been annotated as "others," ensuring they are excluded from any further analysis. Lastly, objects that are difficult to distinguish between each other, such as low vegetation and some connected trees, have been classified as stuff classes. This is particularly relevant for objects that have a similar appearance and are difficult to differentiate. In summary, the annotation process for this dataset has been carried out with the utmost care and attention to detail, resulting in a high-quality dataset that is well-suited to a wide range of research applications.
Statistics
Upon closer inspection of the table, it becomes apparent that some categories contain more instances, although they cover fewer points. For instance, categories such as people and vehicles are densely populated, with a significant number of instances in a relatively small area. These categories are of great interest to researchers due to their prevalence in real-world outdoor environments, making the dataset particularly valuable in developing algorithms for pedestrian detection and vehicle recognition.On the other hand, some categories involve fewer instances, such as electric poles and detectors, which are considered minority classes in instance segmentation. These categories may be less prevalent in real-world environments, but they are still important to include in the dataset as they represent a diverse range of objects commonly found in outdoor environments.
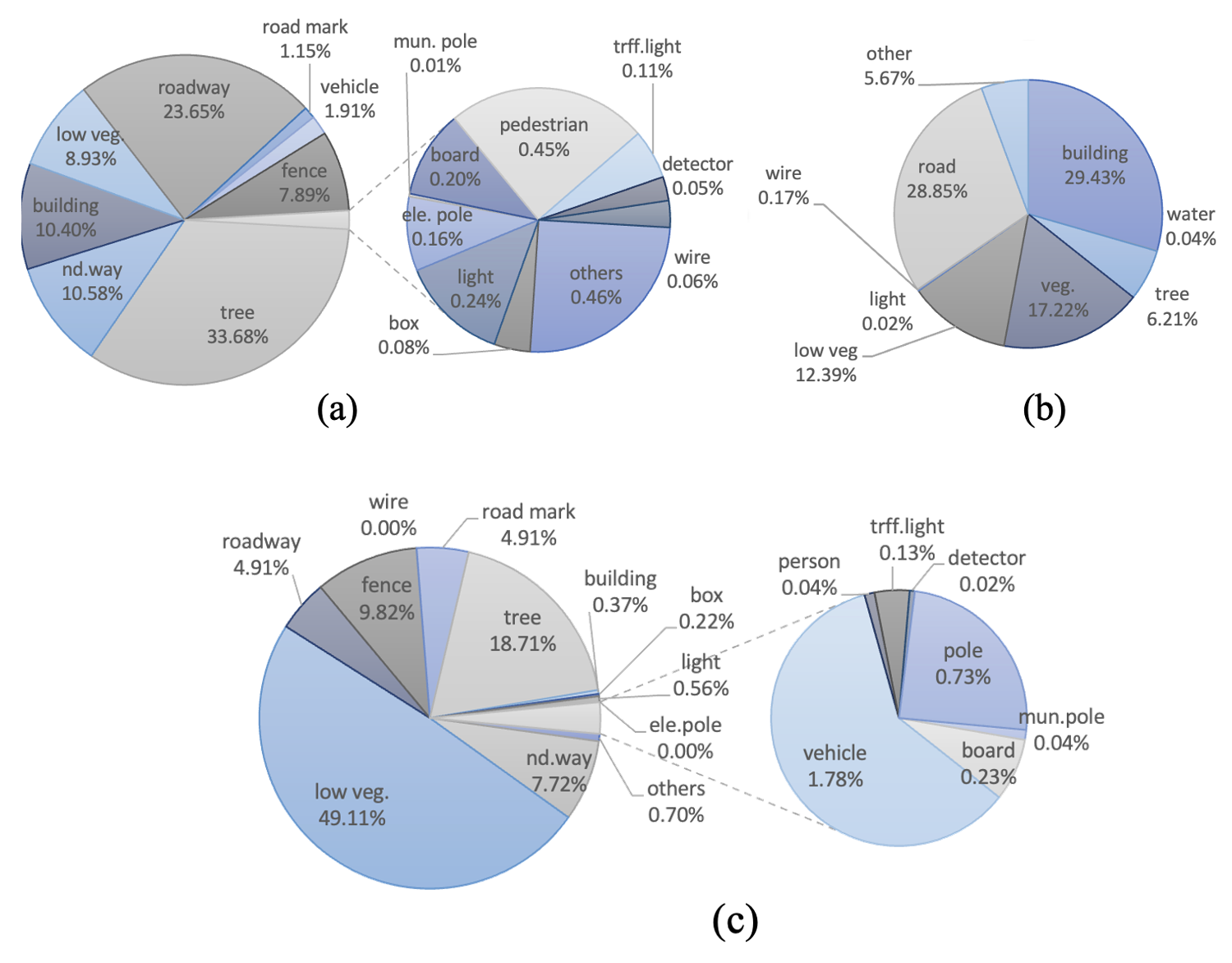
Moreover, by including minority classes, the dataset becomes more comprehensive, allowing researchers to test the accuracy of their algorithms across a wide range of objects and categories. Overall, the inclusion of both heavily populated and minority categories ensures that the dataset is well-suited to a wide range of research applications.
Statistics of MLS-S Annotation
| Label(updating...) | Category | # Ins. | # Scene | Ins |
|---|---|---|---|---|
| 1 | Drive road | - | 40 | ⨉ |
| 1 | Road mark | - | 35 | ⨉ |
| 1 | Well | 111 | 15 | √ |
| 1 | Non-drive road | - | 36 | ⨉ |
| 1 | Ground | - | 24 | ⨉ |
| 1 | Pedestrian | 1355 | 39 | √ |
| 1 | Vehecle | 710 | 39 | √ |
| 1 | Tree | 1979 | 40 | √ |
| 1 | Vegetation | - | 40 | ⨉ |
| 1 | Low vegetation | - | 37 | ⨉ |
| 1 | Parterre | - | 24 | ⨉ |
| 1 | Electrical Pole | 61 | 21 | √ |
| 1 | Board | 224 | 38 | √ |
| 1 | Road light | 327 | 39 | √ |
| 1 | Traffic light | 111 | 23 | √ |
| 1 | Municiple pole | 282 | 21 | √ |
| 1 | Attached board | 85 | 26 | √ |
| 1 | Attached on ele. Pole | 9 | 4 | √ |
| 1 | Attached on lights | 13 | 3 | √ |
| 1 | Detector | 59 | 27 | √ |
| 1 | Building | 119 | 28 | √ |
| 1 | Archetecture | 18 | 9 | √ |
| 1 | Isolation structure | - | 35 | ⨉ |
| 1 | Fence | - | 36 | ⨉ |
| 1 | trash | 113 | 28 | √ |
| 1 | Mailbox | 4 | 3 | √ |
| 1 | Hydrant | 23 | 14 | √ |
| 1 | Bench | 4 | 3 | √ |
| 1 | Box | 81 | 26 | √ |
| 1 | Wire | - | 20 | ⨉ |
| 1 | Shed | 7 | 6 | √ |
| 1 | Bus stop | 24 | 11 | √ |
| 1 | Bus station | 9 | 5 | √ |
| 1 | Stone pier | 49 | 4 | √ |
| 1 | Others | - | 12 | ⨉ |
Statistics of MLS-W Annotation
| Label | Category | #Instances | #Scenes |
|---|---|---|---|
| 0 | Others | - | 4 |
| 2 | Non-drive way | - | 4 |
| 8 | Low vegetation | - | 4 |
| 10 | Driveway | - | 4 |
| 16 | Fence | - | 4 |
| 17 | Wire | - | 0 |
| 11 | Road mark | - | 4 |
| 1 | Tree | 522 | 4 |
| 3 | Building | 8 | 3 |
| 4 | Box | 76 | 4 |
| 5 | Light | 116 | 4 |
| 6 | Electric pole | 0 | 0 |
| 7 | Municipal pole | 136 | 4 |
| 9 | Board | 132 | 4 |
| 12 | Vehicle | 88 | 4 |
| 13 | Person | 16 | 4 |
| 14 | Traffic light | 108 | 4 |
| 15 | Detector | 83 | 4 |
| 18 | Pole | 168 | 4 |
Statistics of ALS-S Annotation
| Label | Cls | # Ins | # Scenes |
|---|---|---|---|
| 200000 | bridge | - | 3 |
| 200101 | building | 1402 | 79 |
| 200200 | water | - | 9 |
| 200301 | tree | 8193 | 75 |
| 200400 | veg | - | 80 |
| 200500 | low veg | - | 75 |
| 200601 | light | 784 | 56 |
| 200700 | electric | 195 | 32 |
| 200800 | ground | - | 80 |
| 200900 | others | - | 57 |
| 100500 | vehicle | 521 | 12 |
| 100600 | non vehicle | 5 | 1 |
MLS-S Dataset
The MLS dataset in city A (MLS-W) includes 38 scenes with average number of points 8 million, of which 28 scenes are split for training and 10 scenes for testing. The dataset in city A can be obtained from here. Some categories are manually labeled as follows.
ALS-S Dataset

Format
H5PY file
Data preprocess
Before the annotated labels being used for training and testing, the following processes are recommended.
- Point Translation. All the points are translated to where the minimum coordinates of the whole scene is (0, 0, x).
- Normal computing. Compute normals for all points as input features with the size of neighborhood 0.8(m).
- Label mapping. Map all the class labels to [0, number of classes] and merge the similar categories.
- Block division. Divide each scene into several blocks if it cannot be directly input into the network due to the large number of points. After block division, the instance labels are supposed to be mapped into consecutive numbers from 0.
- Format conversion. The published format of the dataset is "txt" which is not appropriate for loading training or testing data. Therefore, the dataset should be converted to other formats, such as h5py, npy, pkl, etc.
The provided tool will map the label according to this table(only for MLS dataset of city A, the labels of city B is from 0 to 18):
| 100100→3 | 100901→0 | 101801→0 | 105200→7 |
|---|---|---|---|
| 100200→0 | 100951→0 | 102000→1 | 105300→15 |
| 100300→1 | 101100→5 | 102200→17 | 105400→4 |
| 100400→9 | 101200→6 | 102400→10 | 105500→0 |
| 100500→12 | 101300→5 | 102600→2 | 105600→0 |
| 100600→13 | 101400→6 | 102800→16 | 105700→17 |
| 100700→0 | 101500→9 | 104002→2 | 105800→16 |
| 100801→4 | 101600→8 | 104202→11 | 106100→2 |
| 100851→0 | 101701→0 | 105100→14 | 106200→8 |
| 200000→2 |
Updated Information
😶Please be aware that certain H5-formatted scenes, which are not incorporated in either the training or testing splits, may be omitted. For instance, '0010.h5' from the ALS dataset is excluded because it does not represent 'good' data.
Citation
@article{HAN2024500,
title = {WHU-Urban3D: An urban scene LiDAR point cloud dataset for semantic instance segmentation},
journal = {ISPRS Journal of Photogrammetry and Remote Sensing},
volume = {209},
pages = {500-513},
year = {2024},
issn = {0924-2716},
doi = {https://doi.org/10.1016/j.isprsjprs.2024.02.007},
url = {https://www.sciencedirect.com/science/article/pii/S0924271624000522},
author = {Xu Han and Chong Liu and Yuzhou Zhou and Kai Tan and Zhen Dong and Bisheng Yang},
keywords = {Point cloud, Semantic instance segmentation, Urban-scale dataset, Machine learning},
}